

说在前面的话
各位朋友好,这是最新一期的 AIGC 每周看点,感谢阅读!
本期为第 14 期,内容覆盖 6 月 26 日至 7 月 2 日的 AI 行业相关动态信息;
前两天我说要转移发布内容平台至 Substack,这是在 Substack 正式发布的第一篇内容。但我同时忽略了一个严重问题:Substack 在国内无法正常访问 😓 这与我最初希望调整发布平台但不影响被阅读的目的相差甚远。
经反复研究,现重新调整如下:
使用邮箱订阅的朋友将继续收到来自 Substack 的推送;
使用微信订阅的朋友将继续收到来自 竹白 的推送;
使用微信公众号的朋友可考虑订阅公众号:山甫樂(因内容与样式受限较多,公众号不会更新 AIGC 每周看点 栏目,);
此外也可以访问我的个人站点 Yishan 查看 阅读共鸣 的往期内容(暂不提供订阅)
感谢各位朋友的支持 🙏
本周内容概述
AI 行业的布局与发展
权利主张与国家竞争
AI 对我们的影响及适应
其他 5 条值得关注的新闻
4 款 AI 产品
3 个指南与 3 个最佳实践
3 篇论文与 3 门课程
以及其他一些趣味信息

01
布局与发展

从硬件基建到模型训练,从文本与图像生成服务到多模态业务的探索,围绕大语言模型的产品形态丰富,不同体量的场内玩家也都在逐渐加强自己的竞争力。
近期媒体曝光,OpenAI 计划推出人工智能软件应用商店,和现在的插件功能不同,这里的应用是指其它开发者使用自己技术构建的模型,如企业用户会感兴趣的特定行业模型,基于内部文档回答定向领域的问题等。
此外,根据 The Information 报道,OpenAI 也计划进入商业市场,向企业提供类似办公助手之类的应用。这可能会加剧企业和监管机构对于企业信息和数据安全的担忧,同时也和 OpenAI 的投资方 Microsoft 正计划通过 Windows 系统向终端用户提供类似的人工智能 Copilot 相似。
从 ChatGPT Plugin 到 API 的 Function Calling,可以看出 OpenAI 正从多方面丰富自己商业化的能力,也不会忌讳和自己深度合作的微软展开竞争。
近日,大数据巨头 Databricks 以13亿美元的价格买下AI初创公司 MosaicML,为企业提供统一的平台管理数据资产,并且能够使用专有数据来构建、拥有和保护自己的生成式 AI 模型。根据新闻稿,在 Databricks 和 MosaicML的平台和技术支持下,企业训练和使用 LLMs 的成本将显著降低,预计可以降至数千美元左右。
大型公司对初创公司的收购代表了部分公司对当前市场方向的判断,如果自研的时间与金钱成本都难以抢占先机,或者在细分领域尽快建立优势,不如直接整合已经做得不错的团队。这些收购对于钻研专业领域业务的团队也是一种激励和选择。
如上个月刚获得 1,900 万美元 A 轮融资的音频 AI 公司 ElevenLabs,他们提供的工具可以生成合成语音、克隆语音,或根据性别、年龄和口音偏好定制全新的人工语音,也可以将任何文本转换为语音,所实现的语音质量水平与真人接近。
在消费者市场,ElevenLabs 推出的 Projects 项目使用户能够在不离开平台的情况下无缝生成整个对话片段、新闻文章甚至有声读物。与 Speech Synthesis(一种利用预先存在的合成语音的文本转语音平台)和 VoiceLab(一种用于创建独特语音或现有语音的数字版本的工作流程)一起构成功能强大的产品套件。
延展阅读:
02
权利与竞争

在生成式图像已经引发了关于版权问题的讨论,并且已经有针对生成式服务的版权诉讼时,Adobe 公司展现了他们对其旗下 Firefly 生成式图像工具服务在版权领域的信心。
Adobe 数字媒体副总裁克劳德·亚历山大 (Claude Alexandre) 表示,Adobe 对 Firefly 尊重创作者受版权保护的图像的能力充满信心,如果企业因其工具创建的任何图像而被起诉侵犯版权,Adobe 将依法全额赔偿企业。
虽然这些表态仍然存在一些不明确的地方,同时关于用于模型训练的 Adobe Stock 素材将以什么形式补偿 创作者也未明确。但 Adobe 在生成式服务遭受版权不信任的早期阶段能够做出这一声明,对其他提供类似服务的公司或团队做出了表率。即便这种表率基于 Adobe 长期已经对于版权的重视,以及法律团队对类似版权纠纷处理的熟悉程度。
在媒体领域,OpenAI、谷歌、微软和 Adobe 近几个月正在与新闻出版商展开讨论,讨论围绕文本聊天机器人和图像生成器等人工智能产品的版权问题,尝试达成付费使用出版内容来训练生成人工智能模型的协议。
在互联网时代早期,传统媒体的商业模式被免费的在线文章破坏,谷歌和 Facebook 等大型科技集团使用这些内容建立起各自价值数十亿美元的在线广告业务。
媒体行业希望避免这种事情再次发生。目前的一些讨论涉及为作为训练数据的新闻内容制定定价模型。一个可能的数字是每年 500 万至 2000 万美元。
对 AI 行业来说,其所面临的监管问题可能更为迫切。
Hugging Face 首席执行官兼联合创始人克莱门特·德兰格 (Clement Delangue)最近在国会听证会上,对人工智能社区应该保持模型开源(并承担被滥用风险)和选择由少数巨头控制的闭源之间,选择执行一种“开放加问责”的机制。
开放的目的是增强透明度,同时也促进外部审查。这与德兰格最近响应另一人工智能初创公司 Anthropic 的呼吁相呼应。在呼吁中,Anthropic 建议增加对美国国家标准与技术研究所 NIST 的投资,以提高人工智能的透明度,也能够有利于跨部门研究人员合作解决人工智能风险。
针对行业领域的权益保护和权利争取进行的同时,更高层面的竞争也在加剧。
据 WSJ 报道,美国商务部可能最快在下月初采取行动,禁止英伟达和其他芯片制造商在事先未获得许可证的情况下向中国客户出口芯片,同时也在考虑限制向中国 AI 公司出租云服务。
但显然,执行这种动作的同时,也可能会对美国国内、以及欧盟等相关区域、行业公司产生一些影响,这些影响可能覆盖了从硬件到消费者产业等多方面。
延展阅读:
03
影响与适应

最近半年,使用 GPT 等语言模型学习语言的人越来越多。像 Duolingo、LanguageBuddy 等应用在自己的学习路径中加入了 AI 功能,也有不少新应用是基于语言模型从头全新打造的学习旅程。
一名受访用户指出,许多人会因为在自己不熟悉的语言中犯错误而感到难为情,即使是在课堂上面对老师时也是如此。但使用聊天机器人学习时,AI 不会评判你。同时,与枯燥的预设角色扮演不同,使用 AI 学习语言时,你可以谈论你感兴趣的事情。
但人工智能同样存在缺点,比如更精通被广泛使用的语言,面对小语种则显得能力有限。又比如发明新单词,自信地表述不正确的内容,有时甚至是存在偏见的内容。
生成式人工智能存在“幻觉”与“偏见”的问题长期存在,虽然研究人员一直在努力降低出现这种问题的概率,但在完全解决这个问题之前,人们还是面临这些幻觉与偏见所产生的潜在影响。
Science 第 6651 期的一篇文章指出,生成式人工智能模型存在不切实际和夸大的能力渗透,以及过度炒作,这导致了人们普遍的误解,认为这些模型超出了人类水平的推理能力,并进一步加剧了模型向人们传播虚假信息和负面刻板印象的风险。
同时,与人类常见的“我认为”、反应延迟、不流利语言这些表示着不确定性的信息不同。生成模型本身自信、流畅的响应和表达,带来了强烈的确定性,这些信号也会导致产生更大的信息失真,并影响与之交谈的人类相关理解与认知。
不过这些问题在机械性工作、或者不存在道德评价的工作上显得无足轻重。
瑞士联邦理工学院 (EPFL) 的一组研究人员在零工工作平台上雇佣了 44 名众包员工,让他们总结 16 篇医学研究论文的摘录。根据研究结果,研究人员判断有 33% 到 46% 的员工使用了包括 ChatGPT 在内的人工智能模型来生成工作结果。
这项研究表明,或许已经有不少使用人工智能生成的数据,用来作为训练人工智能的素材。这种无法完全规避、去除的错误信息,在人工智能生成-训练的循环过程中,不可避免地会被放大,并且难以溯源。
解决这个新问题,或许需要模型研究人员、众包平台审核人员,以及众包工作发包人的更多努力。或许一劳永逸的方法是完全避免众包人提交使用 AI 生成的内容?
可惜我们现在也没有掌握准确判断 AI 生成内容的工具。
延展阅读:
🗞️ 其他资讯

Harvard is bringing its own brand of generative AI to the classroom,哈佛大学最近宣布在其最受欢迎的课程之一 CS50 中向学生提供生成式人工智能作为教学资源。为了加强对 CS50 学生的支持,哈佛正在推出自己专有的大型语言模型,为学生提供反馈、调试支持,并协助解决错误、代码和其他与解决方案相关的问题。
YouTube 集成人工智能配音工具,YouTube 在周四的 VidCon 上宣布正在测试一款与人工智能配音服务 Aloud 合作的新工具,该工具将帮助创作者使用人工智能自动将视频配音成其他语言。该服务是 Google 内部孵化器 Area 120 的一部分。
百度表示自己的 Ernie AI 聊天机器人比 OpenAI 的 ChatGPT 更好,最新版本的 Ernie AI 模型 Ernie 3.5 在多个关键指标上超越 ChatGPT。百度强调了 Ernie 3.5 与 ChatGPT 相比综合能力得分更优异,并且在多项中文能力上优于 GPT-4。
Poe 增加了 PaLM 2 机器人,基于谷歌 PaLM 2 chat-bison-001 模型,但遗憾的是试用过程中总觉得不是太智能,或许是因为 API 调试的问题(相同模型驱动的 Bard 和 Workspace 都要显得更流畅一些)
马克·安德森表示,我们处于人工智能的“冻结时刻”,他认为,得益于人工智能,整个经济体的生产力增长将急剧加速,推动经济增长、创建新产业、新就业机会、增长工资,全球将进入物质更加繁荣的新时代。但此时此刻,人们仍在感受新工具带来的激动中,并略微地不知所措。
🛠️ 产品与工具
EmbedAI,创建自己的 AI 聊天机器人;
DragGAN-Windows-GUI,dragGAN 离线桌面端,内置 17 个模型;
ChatPDF,开源的 PDF 对话项目,基于 Langchain + LlamaIndex;
Novel,Notion 风格的可视化编辑文档,支持接入 AI 能力;
☝🏼 指南与最佳实践
讲解向量数据库的视频,借助图形能够更好地理解向量数据库;
ClickPrompt,专为 Prompt 编写者设计的工具,能够根据需求轻松创建符合要求的 Prompt;
来自 @starzqeth 的 播客摘要方法,使用 Modal Podcast Transcriber 提取 (Spotify) Podcast 的字幕,然后用 Glarity一键生成摘要 ;
@satoshimilk 分享的电影风格图像创作工作流程,使用了 Midjourney, Adobe 和 Figma 等工具;
@9hills 分享的《大语言模型(LLM)后训练数据准备相关笔记》;
🎓 课程,讲座与论文
北大ChatExcel课题组开源中文法律大模型,针对LLM和知识库的结合问题给出了法律场景下合理的解决方案,基于姜子牙Ziya-LLaMA-13B-v1 和 Anima-33B 分别训练了 13B 和 33B 版本,优势各异,此外基于 BERT 训练了基于 93 万条判决案例做的相似度匹配模型 ChatLaw-Text2Vec (github);
Self-Supervised Evaluation for Large Language Models,自我监督评估的大语言模型,分析LLM对提示变换的敏感性或不变性,使用自我监督评估远程依赖、闭门知识、语法结构、标记化错误和毒性等,补充了当前依赖标记数据的评估策略 (abs);
**通过具有类似大脑听觉特征的生成模型从人脑活动中重建声音,将大脑对听觉特征的解码与音频生成模型相结合,**利用功能磁共振成像对自然声音的反应,借助深度神经网络(DNN)的分层声音特征斤进行解码并重建声音 (abs);
Generative AI with Large Language Models,Deep Learning 和 AWS 合作的课程;
斯坦福大学的 ML·Systems 研讨会,涵盖各种机器学习系统主题;
Kaggle 的机器学习和数据处理相关课程,区分了不同级别,适合初学者;
💡 Mist.
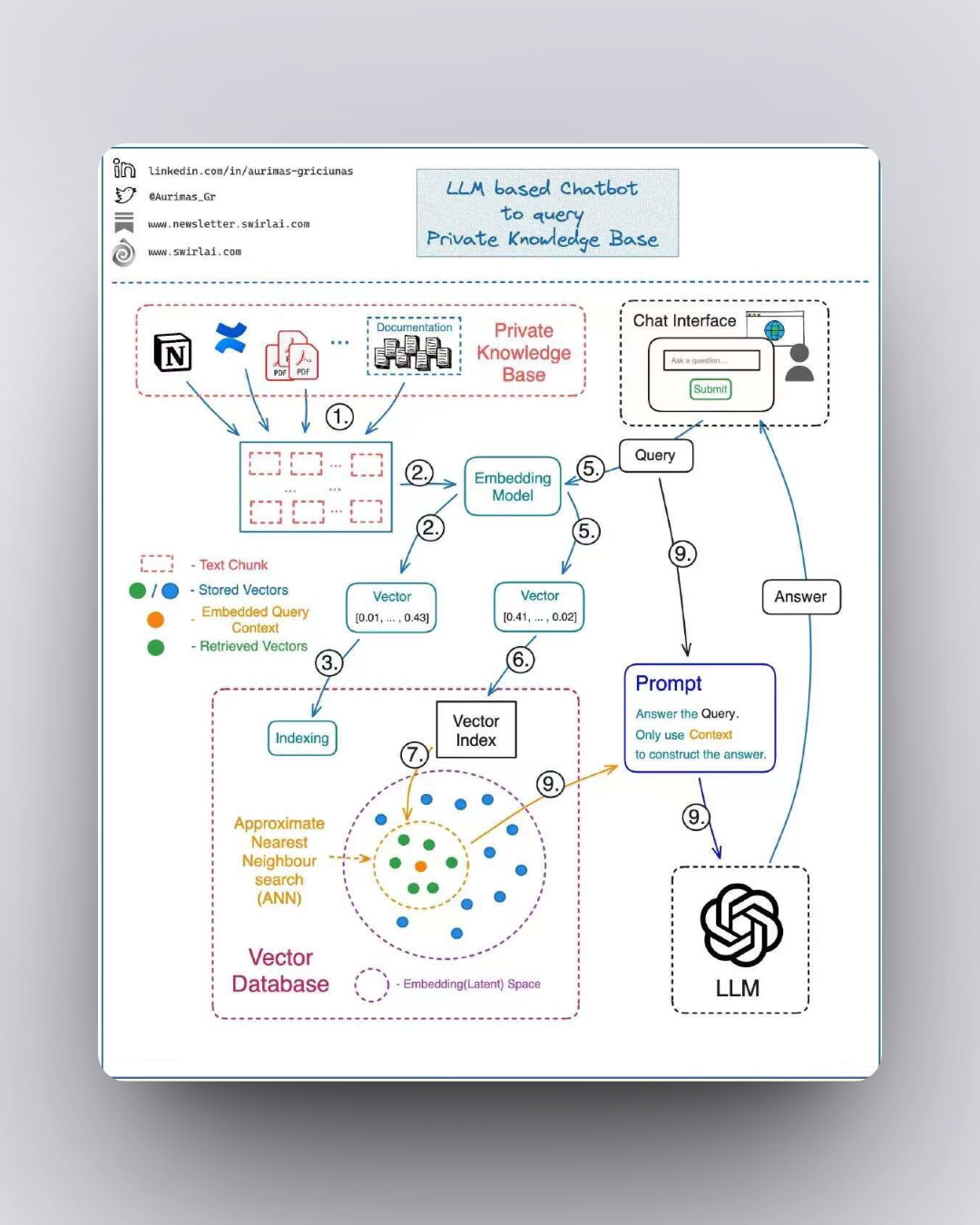
基于机器学习模型(LLM)的聊天机器人的工作流程;
100,000 个虚构的人物照片(链接)
🎨 Gallery
本周图片源于 Midjourney 的 Bug,出现了一次 Grid 图和 Upscale 图完全不搭的情况,通过查询 Job ID 和 Seed ID 发现是 Grid 出现的问题,这种图像“幻觉”还是第一次见到。而下图则是那张被我发现出现错误后再 Zoom out 了一次的图。
mexican, street, illustrator, 80s, poem, post-modern building --ar 8:5

(完)